
May 15, 2025
Ensuring Excellence in Patient Care with Qu
Quadrivia's first manual clinical quality assurance framework for safe and effective patient interactions with clinical AI assistants
At Quadrivia, we're dedicated to developing Qu, our clinical AI assistant to be the most effective and trustworthy clinical AI assistant in healthcare. But how do we ensure Qu is safe, reliable, and delivers exceptional patient experiences?
We've created a rigorous, hands-on Manual Clinical Quality Assurance Framework to guide our development and continuous improvement of Qu.
Why Quadrivia Prioritizes Manual Quality Assurance
Manual testing is critical in our approach because it helps us achieve:
- Patient Safety: We prioritize preventing any harm.
- Reliable Performance: Qu must consistently deliver accurate and trustworthy interactions.
- Outstanding User Experience: Patients deserve empathetic, clear, and engaging interactions every time.
We're building Qu to conduct outbound patient calls, offering seamless support while providing clear, precise transcripts and summaries for healthcare providers. To ensure Qu consistently meets high standards, robust evaluation is essential.
Our Comprehensive Testing Approach for Qu
Here’s how our Manual Clinical Quality Assurance Framework works:
Clinical Scenario Simulations
Our clinical team manually simulates realistic patient interactions covering:
- Routine, everyday scenarios
- Complex patient cases
- Unexpected edge cases
These simulations ensure Qu is prepared for the wide range of conversations it will encounter in real clinical environments.
Structured Interaction Scoring
Every interaction Qu has is evaluated through clearly defined checkpoints across three critical clinical domains:
- Data Gathering: Does Qu accurately and comprehensively collect patient information?
- Interpersonal Skills: Does Qu communicate clearly, empathetically, and engage effectively?
- Clinical Skills: Are interactions clinically safe, accurate, and relevant?
Our scoring system is straightforward and actionable:
- 0 = No/Not Done
- 1 = Partially Done
- 2 = Yes/Done

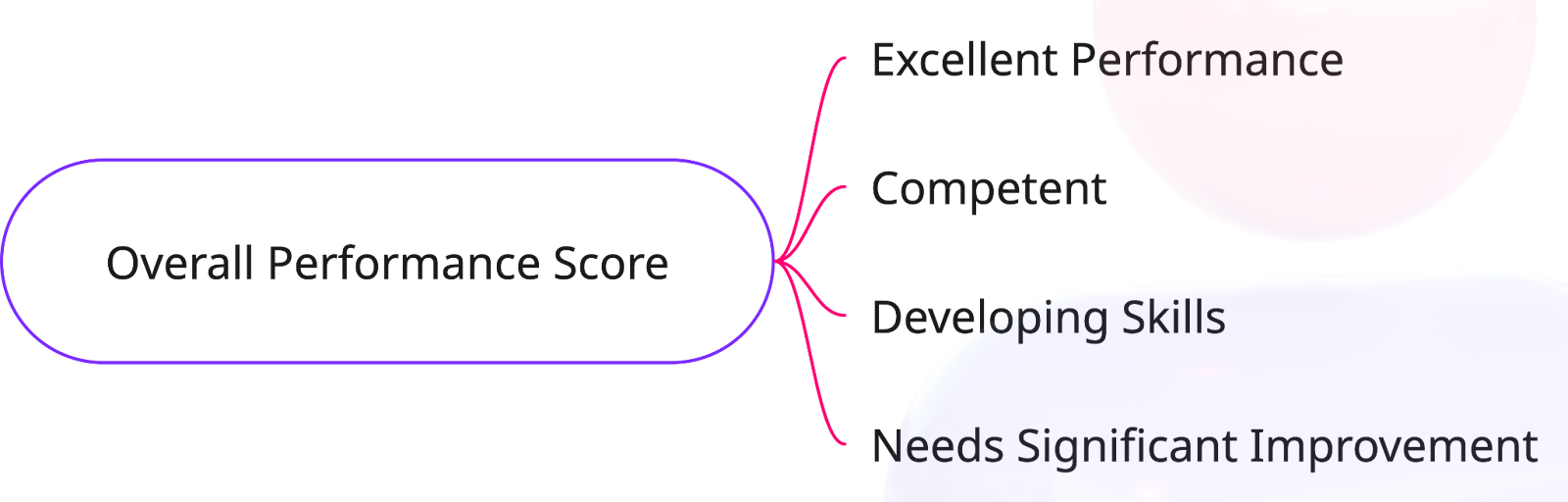
Overall Performance Ratings
Following these detailed evaluations, Qu receives an overall performance rating:
- Needs Significant Improvement
- Developing Skills
- Competent
- Excellent Performance
These ratings help our teams quickly pinpoint areas for Qu's ongoing improvement.
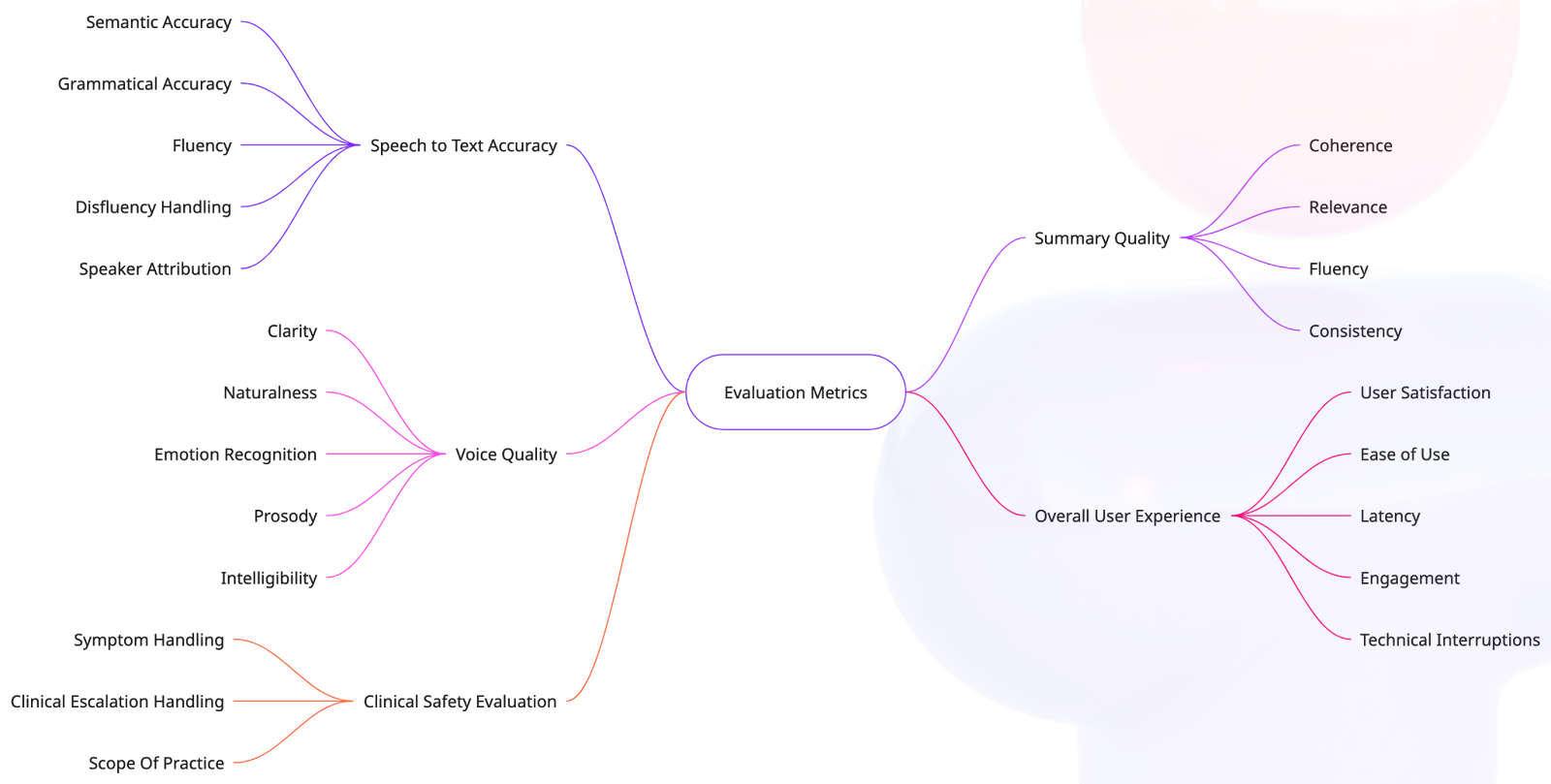
Additional Targeted Quality Checks
Our framework also includes targeted checks across critical quality dimensions:
Speech & Voice Quality
- Accurate speech-to-text transcription
- Clarity, tone, and consistency of voice interactions
Clinical Safety
- Safe symptom management
- Appropriate patient care escalation
- Adherence to defined clinical boundaries
Call Summary Quality
- Relevance, clarity, and accuracy of generated summaries
User Experience & Technical Reliability
- Smooth, engaging interactions
- Swift identification and resolution of technical issues
Harm Severity Assessment
Patient safety is paramount. We leverage the Agency for Healthcare Research and Quality (AHRQ) Harm Classification Scale to assess potential patient safety risks comprehensively, categorizing severity from 'No Harm' to 'Death.' This enables Quadrivia to proactively manage and mitigate safety concerns.
Through this robust, manual Quality Assurance Framework, Quadrivia is committed to ensuring Qu represents the forefront of safe, effective, and patient-focused clinical AI, delivering the highest standards of healthcare innovation.
You might also like
Read more about our technology and vision
Download our whitepaper to learn more about what Qu can do, how it works and how we've built it
Download our whitepaperContact
To report bugs, security vulnerabilities,
or privacy concerns, please contact
support@quadrivia.aior privacy concerns, please contact
